Introduction
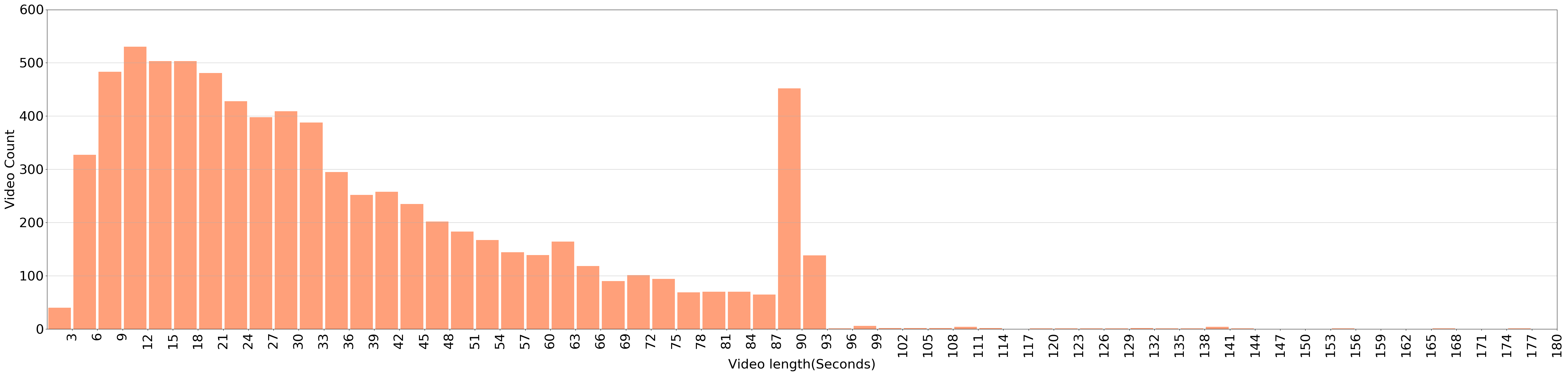
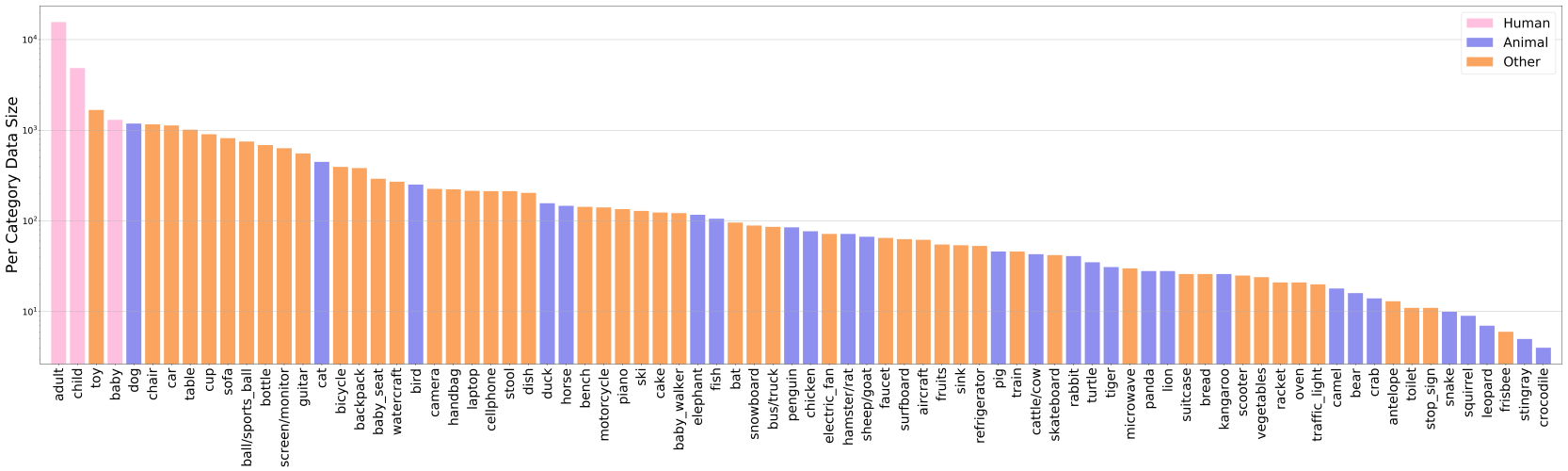
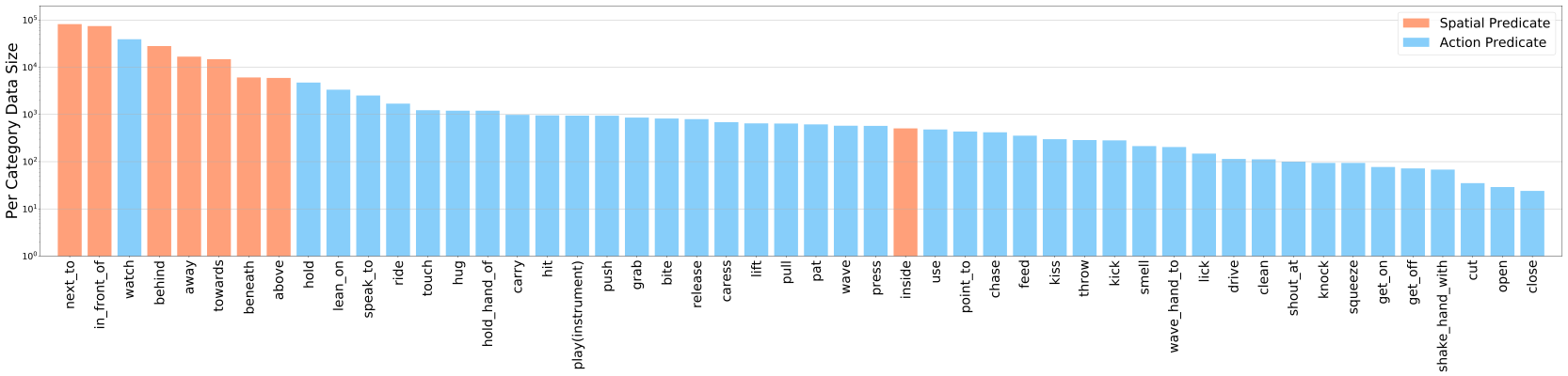
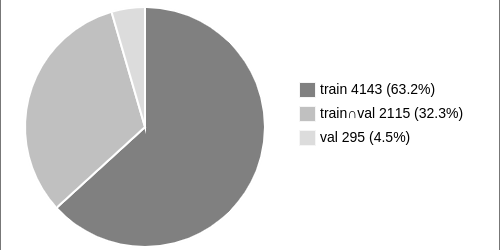
VidOR (Video Object Relation) dataset contains 10,000 videos (98.6 hours) from YFCC100M collection together with a large amount of fine-grained annotations for relation understanding. In particular, 80 categories of objects are annotated with bounding-box trajectory to indicate their spatio-temporal location in the videos; and 50 categories of relation predicates are annotated among all pairs of annotated objects with starting and ending frame index. This results in around 50,000 object and 380,000 relation instances annotated. To use the dataset for model development, the dataset is split into 7,000 videos for training, 835 videos for validation, and 2,165 videos for testing. VidOR can provide foundation for many kinds of research and has been used in:
- ACM Multimedia 2019 Grand Challenge
- ACM Multimedia 2020 Grand Challenge
- ACM Multimedia 2021 Grand Challenge
- VidSTG: a dataset for video grounding
- NExT-QA: a video QA dataset for explaining temporal actions
- VidOR-MPVC: a video captioning dataset for multi-perspective visual captioning